| OpenCL专题03:程序框架详解(以并行化向量相加为例) | 您所在的位置:网站首页 › opencl introduction › OpenCL专题03:程序框架详解(以并行化向量相加为例) |
OpenCL专题03:程序框架详解(以并行化向量相加为例)
|
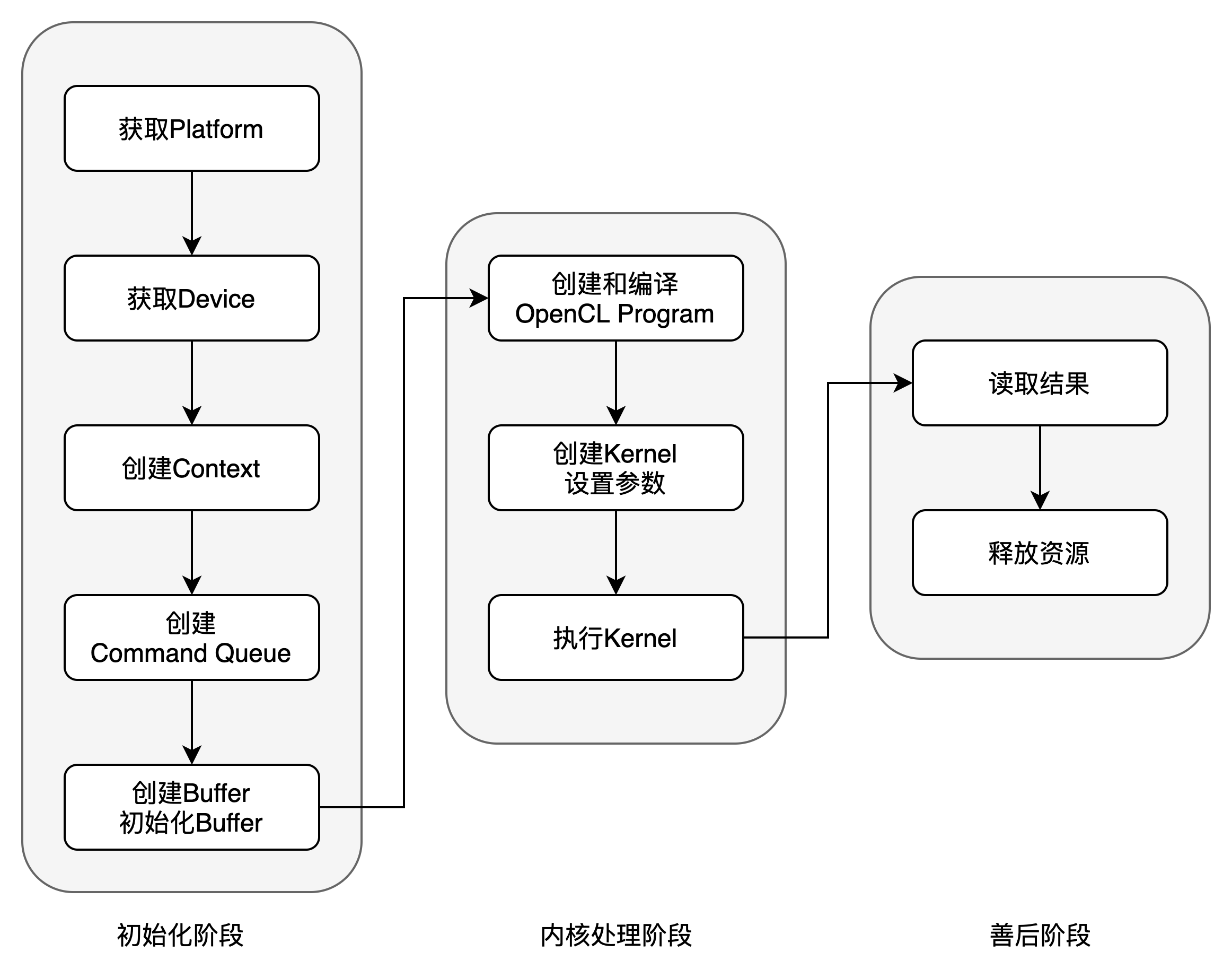
1. 基本框架
开发一个OpenCL程序,包括三大阶共10个步骤。 我们通过一个案例来对各步骤进行说明。案例是实现两个向量相加,所得结果放在第三个向量中。通过OpenCL,利用GPU并发执行。 2.0 引入头文件并定义一个异常类 #define CL_TARGET_OPENCL_VERSION 220 #include #include #include #include #include using namespace std; class OCLException { public: int type;//0:Error, 1: Warning int ID; string content; OCLException(int type, int ID, string content) { this->type=type; this->ID=ID; this->content=content; } }; int main() { //程序主体部分,下文分步解释 }这里定义了一个异常类OLException,统一处理程序运行中出现的错误、警告等。 该类中预设三个属性: type:异常类型(0为错误,1为警告)ID:异常编号(在编写程序时,同步维护异常码表)content:异常说明 2.1 获取Platform cl_int ret; //step1: 获取平台 cl_uint num_platforms; cl_platform_id platform_ids[5]; char param_value[100]; size_t param_value_size_ret; ret = clGetPlatformIDs(0, NULL, &num_platforms); if(ret!=CL_SUCCESS) throw new OCLException(0,1,"clGetPlatformsIDs Error"); if(num_platforms==0) throw new OCLException(1,1,"no platform found"); cout cout host_A[i]=i; host_B[i]=i; } buffer_A=clCreateBuffer(context,CL_MEM_READ_ONLY|CL_MEM_USE_HOST_PTR,BUFFER_SIZE,host_A,&ret); if(ret!=CL_SUCCESS) throw new OCLException(0,10,"clCreateBuffer Error"); buffer_B=clCreateBuffer(context,CL_MEM_READ_ONLY|CL_MEM_USE_HOST_PTR,BUFFER_SIZE,host_B,&ret); if(ret!=CL_SUCCESS) throw new OCLException(0,12,"clCreateBuffer Error"); buffer_C=clCreateBuffer(context,CL_MEM_WRITE_ONLY,BUFFER_SIZE,NULL,&ret); if(ret!=CL_SUCCESS) throw new OCLException(0,13,"clCreateBuffer Error"); cout int index=get_global_id(0); C[index]=A[index]+B[index]; } __kernel限定符用来限定内核函数,且返回值必须为void。__global限定变量在GPU的全局内存上,其它还有__constant常量全局内存,__local本地内存,在同一个work-group中可见,以及私有内存__private,所有未标明限定的都是私有变量,只在同一个work-item中可见。get_global_id函数返回所请求维度上,执行该函数的work-item的全局索引。函数的参数指定第几维。类似的内核函数还有: get_work_dim(),返回NDRange的维度(1,2,3) get_global_size(uint dimension),返回所请求维度上work-item的总数 get_global_id(uint dimension),返回所请求维度上执行该函数的work-item的全局索引。 get_local_size(uint dimension),返回在所请求维度上work-group的大小 get_local_id(uint dimension),返回在所请求维度上当前work-item在work-group中的索引 get_number_groups(uint dimension),返回所请求维度上work-group的数目=global_size/local_size 2.7 创建kernel加载到GPU上的program编译后,利用编译成功的program创建内核对象,并为内核对象的参数赋值。 //step7: 创建kernel cl_kernel kernel=clCreateKernel(program, "vecadd", &ret); if(ret!=CL_SUCCESS) throw new OCLException(0,17,"clCreateKernel Error"); ret=clSetKernelArg(kernel, 0, sizeof(cl_mem), &buffer_A); if(ret!=CL_SUCCESS) throw new OCLException(0,18,"clSetKernelArg Error"); ret=clSetKernelArg(kernel, 1, sizeof(cl_mem), &buffer_B); if(ret!=CL_SUCCESS) throw new OCLException(0,19,"clSetKernelArg Error"); ret=clSetKernelArg(kernel, 0, sizeof(cl_mem), &buffer_C); if(ret!=CL_SUCCESS) throw new OCLException(0,20,"clSetKernelArg Error");其中,通过clCreateKernel函数创建内核对象,通过clSetKernelArg函数为内核对象的参数赋值。 cl_kernel clCreateKernel(cl_program program, //编译成功的OpenCL程序 const char *kernel_name, //是OpenCL程序中用__kernel限定符声明的函数名 cl_int *errcode_ret) //错误码 cl_int clSetKernelArg(cl_kernel kernel, //内核对象 cl_uint arg_index, //内核函数中的参数序号 size_t arg_size, const void *arg_value) arg_size指定参数的size。若参数类型为内存对象(memory object),则arg_size设定为sizeof(cl_mem)。若参数被声明为__local,则arg_size设定为需要为该本地对象分配的buffer的字节数。 2.8 执行kernel //step8: 执行kernel size_t dim = 1; size_t global_work_offset[] = {0}; size_t global_work_size[] = {ARRAY_SIZE}; size_t local_work_size[] = {64}; ret=clEnqueueNDRangeKernel(command_queue, kernel, dim, NULL, global_work_size, NULL, 0, NULL, NULL); if(ret!=CL_SUCCESS) throw new OCLException(0,21,"clEnqueueNDRangeKernel Error");OpenCL编程中的一个核心函数是clEnqueueNDRangeKernel,对于此函数的理解,有利于对数据在host和device之间的传递进行控制。 cl_int clEnqueueNDRangeKernel(cl_command_queue command_queue, //有效的命令队列 cl_kernel kernel, //有效的内核对象 cl_uint work_dim, //用于指定全局工作项和工作组中工作项的维度数 const size_t *global_work_offset, //当前版本必须为NULL,未来可用于描述工作项的全局偏移 const size_t *global_work_size, const size_t *local_work_size, cl_uint num_events_in_wait_list, const cl_event *event_wait_list, cl_event *event) global_work_size指向一个work_dim维度的无符号整数数组,这些值描述将执行内核函数的全局各维度中的work-item的数量。work-item的总数按global_work_size数组中各维的work-item数量的乘积计算。该总数不能超过设备的内存寻址大小,比如设备使用32位寻址空间,则global_work_size数组中各维度数值的乘积不能超过2^32.local_work_size指向一个work_dim维度的无符号整数数组,该数组描述组成work-group的work-item数量。work-group中工作项的总数按local_work_size数组中各维的work-item数量的乘积计算。工作组中工作项的总数不能大于CL_DEVICE_MAX_WORK_GROUP_SIZE值(该值可通过终端下的clinfo命令查看,或通过clGetDeviceInfo函数查询),并且在local_work_size各维度中指定的work-item数必须小于或等于指定的CL_DEVICE_MAX_WORK_ITEM_SIZES各维度中的值。local_work_size 大小也可以是空值,在这种情况下,OpenCL将自动决定如何将全局工作项分解为适当的工作组实例。如果指定了local_work_size,则在global_work_size中指定的各维度work-item数必须可以被local_work_size对应维度中指定的work-item数整除。event_wait_list和num_events_in_wait_list指定执行此特定命令之前需要完成的事件,可以为空。如果event_wait_list为空,则此特定命令不会等待任何事件完成,且num_events_in_wait_list必须为0。如果event_wait_list不为空,则其所指向的event_wait_list必须有效,且num_events_in_wait_list必须大于0。事件等待列表中指定的事件充当同步点。与event_wait_list和command_queue中的事件关联的上下文必须相同。event返回标识此特定内核执行实例的事件对象。事件对象是唯一的,可以在以后用于标识特定的内核执行实例。如果event 为NULL,则不会为此内核执行实例创建任何事件,因此应用程序将无法查询或排队等待此特定的内核执行实例。 2.9 读取结果 //step9: 读取结果 clEnqueueReadBuffer(command_queue, buffer_C, CL_TRUE, 0, BUFFER_SIZE, host_C, 0, NULL, NULL); for(int i=0;i |
【本文地址】
公司简介
联系我们